Supercharge your filters and dynamic tags with RegEx
KeywordsLearn how to use RegEx in AccuRanker
What is RegEx in SEO?
RegEx, short for regular expressions, is a powerful tool used to search for patterns in text. It can be used to group keywords or URLs that match the same pattern. In this help guide, we will look at how you can use RegEx in AccuRanker to supercharge your filtering.
What can RegEx do?
RegEx can be used to create both simple and complex groups of keywords and URLs. A very simple example would be to find all keywords that contain "seo" or "rank tracker" or "accuranker". You can do this with the following pattern: seo|rank tracker|accuranker. Simply paste this into your keyword filter as shown in the image below.
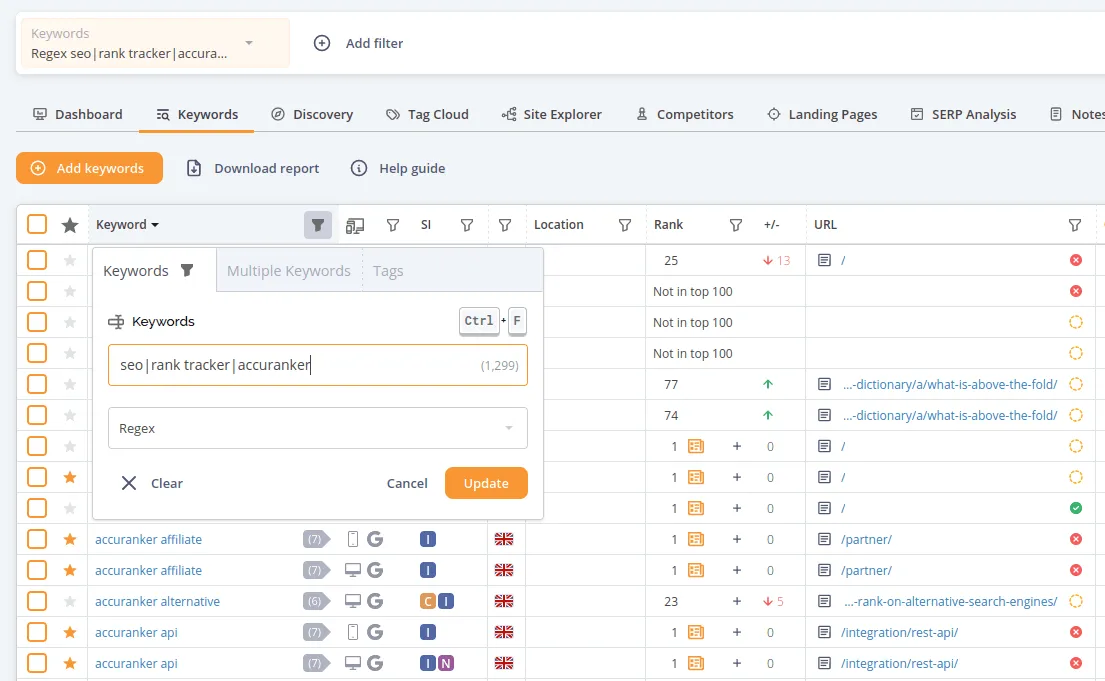
You can also get more creative - for example, the following RegEx will find all keywords that start with "accuranker" and then contain any of the words api or affiliate: ^accuranker (api|affiliate). RegEx is an extremely flexible tool - but it is better at looking for matches for certain patterns than looking for patterns where something does not apply. That is why we also have a "Not RegEx" filter, which looks keywords not matching a particular RegEx, Learn more tips and tricks for using RegEx later in this article.
Where can I use RegEx in AccuRanker?
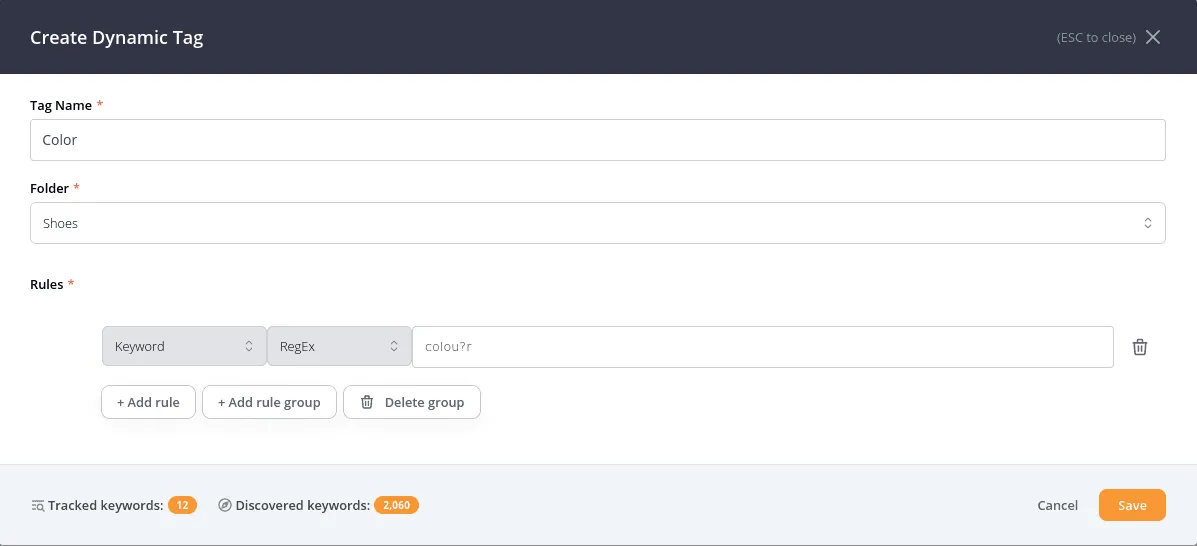
You can use RegEx in the keyword filter and the URL filter on all tabs, including Discovery. You can also use them when creating dynamic tags to apply RegEx filters to keywords, URLs and title tags. Please note, that we only support re2 regular expressions, which supports all the most common use cases and helps keep the filtering blazing fast. RegEx are case sensitive, so it matters if you capitalize words or not. Note that we have both a "RegEx" and a "Not RegEx" filter, where one of them looks for matches, and one looks for phrases that do not match the given pattern!
Usecases for RegEx in SEO
The usecases for RegEx for keyword grouping are many, here are a few examples.
Identifying questions
A simple way to identify questions, would be to apply the RegEx
\b(who|what|where|when|why|how)\b
This regular expression will match "who", "what", "where", "when", "why", and "how" only when these words appear as complete, distinct words in the text. This includes instances where they are at the beginning or end of a sentence, or surrounded by spaces, punctuation, or other non-word characters.
If you only care for sentences starting with one of these words, replace the first \b with a ^.
Identifying long tail keywords
This regular expression will match sentences with more than four words.
(\w+\b\s*){5,}
- (\w+\b\s*): Matches a word followed by a word boundary to ensure the entire word is captured, then allows for any number of whitespace characters to follow. This group ensures that we match a word and any following spaces as a unit.
- \w+: Matches one or more word characters (letters, digits, underscores).
- \b: Asserts another word boundary at the end of the word to ensure we capture full words.
- \s*: Matches zero or more whitespace characters after the word.
- {5,}: This quantifier matches the preceding group (\w+\b\s*) five or more times, ensuring the sentence has at least five words.
Identifying branded searches or product searches
Your brand could be represented by various spellings. For instance, if your brand is Levi's, you might create a RegEx to catch keywords that include Levi, Levi's, or Levis. A straightforward RegEx for this purpose could be: levi|levi's|levis. Furthermore, if you wish to target a specific category of products, such as jeans for Levi's, and you know some of their models are named 501, 502, 511, and 514, a simple RegEx to capture these would be 501|502|511|514. Alternatively, for a more creative approach, you could look for keywords that feature a number in the range of 500 to 599. This can be accomplished with the following RegEx: \b(5\d{2})\b, which looks for a word break, then 5 followed by exactly two digits, and then a word break.
Identifying non-branded searches
Similar to looking for branded searches, you can look for non-branded searches. Apply the same strategy as explained for identifying branded searches, but choose the "Not RegEx" filter instead of the "RegEx" filter!
Regex and ChatGPT
ChatGPT is an awesome tool for creating regular expressions to suit your needs. If you have a ChatGPT subscription, you can use one of the existing custom GPTs, for example RegEx GPT, but there are also tools like AutoRegex that can help you out. Otherwise, you can use our custom prompt which you should insert as the first piece of text in your prompt:
This GPT specializes in creating regular expressions (regex) using re2 syntax. It should always provide the regex first in its response, followed by a short explanation of how it works. The GPT is designed to focus on delivering concise and clear regex solutions, avoiding lengthy discussions or unrelated content. It should ensure the regex provided is accurate and adheres to the re2 syntax guidelines, catering to users who seek quick and reliable regex patterns for their specific needs.
If you want to learn how to make RegEx without the help of AI, the below cheat sheet may be useful!
RegEx cheat sheet
| Character | Example | Matches |
|---|---|---|
| Literal characters | ||
abc | abc | Matches the exact sequence of characters 'abc' |
| Alternation | ||
| (OR) | cat|dog | Matches either the sequence before or after the '|'. Example: 'cat' or 'dog' |
| Special characters | ||
. (Dot) | a.c | Matches any single character except newline characters. Example: 'abc', 'anc', 'a3c' |
^ (Start of string) | ^www | Matches the beginning of a string. Example: 'www.example.com' but not 'site.www.com' |
$ (End of string) | .com$ | Matches the end of a string. Example: 'example.com' but not 'example.company' |
* (Zero or more) | lo*l | Matches zero or more occurrences of the preceding element. Example: 'll', 'lol', 'lool', etc. |
+ (One or more) | lo+l | Matches one or more occurrences of the preceding element. Example: 'lol', 'lool', 'loool', etc. |
? (Zero or one) | colou?r | Matches zero or one occurrence of the preceding element. Example: 'color' or 'colour' |
{n} (Exactly n times) | ho{2}t | Matches exactly 'n' occurrences of the preceding element. Example: 'hoot' |
{n,} (n or more times) | ho{2,}t | Matches 'n' or more occurrences of the preceding element. Example: 'hoot', 'hoooot' |
{n,m} (Between n and m times) | ho{2,3}t | Matches between 'n' and 'm' occurrences of the preceding element. Example: 'hoot', 'hoooot' but not 'hoooot' |
| Character classes | ||
[a-z] | [a-z] | Matches any single character in the range. Example: 'a', 'b', ..., 'z' |
[A-Z] | [A-Z] | Matches any single character in the range. Example: 'A', 'B', ..., 'Z' |
[0-9] | [0-9] | Matches any single digit. Example: '0', '1', ..., '9' |
| Special sequences | ||
\d | \d | Matches any digit. Equivalent to [0-9]. Example: '2', '3' |
\D | \D | Matches any non-digit character. Equivalent to 0-9. Example: 'a', '!' |
\w | \w | Matches any word character (alphanumeric or underscore). Equivalent to [a-zA-Z0-9_]. Example: 'word', '_word' |
\W | \W | Matches any non-word character. Equivalent to a-zA-Z0-9_. Example: '!', '@' |
\s | \s | Matches any whitespace character (spaces, tabs, line breaks). Example: ' ', '\t', '\n' |
\S | \S | Matches any non-whitespace character. Example: 'word', '!' |
| Groups and ranges | ||
() (Grouping) | (abc)+ | Groups multiple tokens together and remembers the text matched. Example: 'abc', 'abcabc' |
(?:) (Non-capturing group) | (?:abc)+ | Groups multiple tokens together but does not remember the matched text. Example: 'abc', 'abcabc' |
Still need help?
Customer support
Our live support team is ready to assist you with any issues.